



pythonでスライドムービー生成プログラム
カテゴリ:Pythonの話
こんにちは。inglowの開発担当です。
今回は、近年超キテる「python」を使って、複数の写真からスライドショーを生成するプログラムを作成してみました
開発環境は下記です。
- バージョン:python3.8.3
- エディタ:notepad++
また、弊社ではWebプロモーション成功事例集をまとめた限定資料を無料で配布しています。
Webマーケティングに興味がある方は、下記ページより目を通してみてください。
今回作るもの
今回は、フォルダにまとめた写真からスライドショームービーを自動で生成するプログラムを作っていきたいと思います。大まかな仕様は下記のような感じです。
- 「photos」フォルダに入っている写真をフェードイン→3秒表示→フェードアウトのような動画にする
- 写真と同じファイル名のテキストファイルがあれば、その内容を写真に表示する(「img_001.jpg」だったら、「img_001.txt」があればこの内容を写真に表示する)
今回は、「あんずもじ」というフォントを使わせていただきました。 - exifデータを読み取って、撮影日を写真に表示する
という感じです。画像をリサイズしたり、文字を入れるために、「openCV」や「Pillow」といったライブラリを駆使していきます。
各処理を順番に作成していきます。
写真画像の加工その1 -リサイズする-
まずは、「photos」フォルダの中の写真ファイルを取得します。
「glob.glob()」関数で指定したフォルダの中のファイルパスを取得することができますので、取得します。
|
1 2 3 4 5 |
import glob #写真読み取りフォルダの指定 photos = base_path + 'photos' + DS files = glob.glob(photos + "*.jpg") |
末尾を、「*.[拡張子]」とすることで、指定した拡張子のファイル一覧のみ取得することができます。
まずは、取得されたパスを順番に処理するプログラムを書きます
|
1 2 |
for file in files: #ここに処理をかいていく |
今回の動画サイズは、「854×480」の動画を生成していきます。これより大きい写真の場合はリサイズする必要がありますが、縦向きの写真と横向きの写真が混ざっているため、横長の写真の場合は、横を合わせて、縦長の写真の場合は縦を合わせるようにリサイズする必要があります。また、写真のサイズが、生成しようとしている動画サイズよりも小さい場合はリサイズしません。これをプログラムで書いていきます
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
for file in files: origin = Image.open(file) #画像を開く image = origin.copy().convert('RGBA') #実際に加工をしていくための変数 #画像をリサイズする if((image.size[0] > video_size[0]) or (image.size[1] > video_size[1])): #縦の方が大きければ縦に合わせる・横のほうが大きければ横に合わせる resize = [image.size[0], image.size[1]] if(image.size[0] > image.size[1]): resize[0] = video_size[0] resize[1] = int(image.size[1] * (video_size[0] / image.size[0])) else: resize[1] = video_size[1] resize[0] = int(image.size[0] * (video_size[1] / image.size[1])) image = image.resize(resize, resample=Image.ANTIALIAS) |
写真画像の加工その2 -exif情報を取得する-
スマホで撮影した写真や、GPS等が搭載されているデジタルカメラ等で写真を撮影すると、その時の位置情報や撮影時間が写真データの中に記録されます。これをExifデータといいます。(自分は「イグジフ」と呼んでいます。)
これらが記録されているためスマホで撮影された写真をSNS等にアップする際には気をつけましょうという話をよく聞きます。(みなさん注意しましょう!)
今回は自分が撮影した写真なので躊躇なくexif情報を抽出します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
for file in files: origin = Image.open(file) #画像を開く #exifから日付を取得する exif = origin._getexif() exif_table = {} for tag_id, value in exif.items(): tag = TAGS.get(tag_id, tag_id) exif_table[tag] = value txt = exif_table['DateTimeOriginal'] #画像リサイズの処理ここから~~~~ |
直接「キー->値」という形で入っているわけではなく、キーはタグのIDになっているため、タグのIDに対して、何のデータが入っているかを生成しなおして、利用しやすくしています。今回は撮影時間が欲しかったので、「’DateTimeOriginal’」キーからデータを取得しました。
写真画像の加工その3 -テキストファイルのテキストを合成する-
写真と同じファイル名のテキストファイルが存在していたら、そのファイル内の文字を写真に入れる処理を作ります。前項で取得した撮影日時の次の行に入れていきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
for file in files: #exifから日付を取得する #テキストファイルがあれば、テキストを追加する if(os.path.exists(photos + fnm + '.txt')): if(txt != ''): #すでにデータがはいっていたら改行する txt = txt + '\n' txtf = open(photos + fnm + '.txt', 'r', encoding="utf-8_sig") txt = txt + txtf.read() txtf.close() #画像リサイズの処理 |
写真に入れる文字が生成できたら、写真に合成していきます。
写真への文字入れのイメージは、文字入れ用のレイヤーを作成し文字を描画して、写真と合わせるといったイメージになります。また、写真は「JPEG」のため、透過情報を持っていません。読み込む際に、「RGBA」モードで読み込む必要があります。
ここまでが、写真の文字入れやリサイズの処理になります。加工した写真は、一時ファイルとして、いったん「tmp」フォルダへ保存します。
画像を読み取り、加工して保存する処理の全容は下記のような感じになります
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
from PIL import Image, ImageOps, ImageGrab, ImageFont, ImageDraw from PIL.ExifTags import TAGS import cv2 import os import glob #base_path="c:\user~~~" DS="/" photos = base_path + 'photos' + DS files = glob.glob(photos + "*.jpg") for file in files: #フレームのベースイメージ 真っ白画像を生成する video_frame = Image.new('RGBA', video_size, (255,255,255,255)) #一時ファイル生成のためのパスの準備 slide_count = slide_count + 1 svpath = tmp_path + "img_" + str(slide_count).zfill(4) + '.jpg' #画像を開く origin = Image.open(file) image = origin.copy().convert('RGBA') txt = '' fnm = os.path.splitext(os.path.basename(file))[0] #exifから日付を取得する 画像加工その2で紹介 exif = origin._getexif() exif_table = {} for tag_id, value in exif.items(): tag = TAGS.get(tag_id, tag_id) exif_table[tag] = value txt = exif_table['DateTimeOriginal'] #テキストファイルがあれば、テキストを追加する 画像加工その3で紹介 if(os.path.exists(photos + fnm + '.txt')): if(txt != ''): txt = txt + '\n' txtf = open(photos + fnm + '.txt', 'r', encoding="utf-8_sig") txt = txt + txtf.read() txtf.close() #動画のサイズにリサイズする 画像加工その1で紹介 if((image.size[0] > video_size[0]) or (image.size[1] > video_size[1])): #縦の方が大きければ縦に合わせる・横のほうが大きければ横に合わせる resize = [image.size[0], image.size[1]] if(image.size[0] > image.size[1]): resize[0] = video_size[0] resize[1] = int(image.size[1] * (video_size[0] / image.size[0])) else: resize[1] = video_size[1] resize[0] = int(image.size[0] * (video_size[1] / image.size[1])) image = image.resize(resize, resample=Image.ANTIALIAS) #画像の中心地点を計算してフレームのベースに合成する p = (round(((video_size[0] - image.size[0]) / 2)), round((video_size[1] - image.size[1]) / 2)) video_frame.paste(image, p) #テキストを合成する if(txt != ''): mask = Image.new('RGBA', video_size, (255,255,255,0)) #今回は手書き風文字「あんずもじ」を使用 font = ImageFont.truetype(base_path + "fonts" + DS + "APJapanesefontT.ttf", 30) draw = ImageDraw.Draw(mask) draw.text((20, 20), txt, fill='#333333', font=font) video_frame= Image.alpha_composite(video_frame, mask) bg = Image.new("RGB", video_size, (255, 255, 255)) bg.paste(video_frame, mask=video_frame.split()[3]) bg.save(tmp_path + "img_" + str(slide_count).zfill(4) + '.jpg', 'JPEG', quality=95) |
動画のフレーム画像の生成
動画にしたい画像ができたところで、次は、フレーム画像の生成をしていきます。
まず、動画の仕組みからですが、ぱらぱら漫画のように、少しずつ変化している画像を連続で流すことで動画になります。ここでは、この「ぱらぱら漫画」の1枚ずつの画像(フレーム)を生成していきます。まずは、1枚の写真で必要なフレーム数を計算します。
動画の流れとしては、1枚の写真を
フェードイン(0.5秒)→画像表示(3秒)→フェードアウト(0.5秒)
と表示して次の写真へ…という流れになります。また、フェードアウトが何フレーム目からはじまったらいいかも必要になります。これらはpythonに計算してもらいましょう
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#1秒当たりのフレーム枚数 fps = 60 #写真1枚当たりのフレーム数 3秒間表示したい image_frm = int(fps * 3) #フェードするフレーム数 0.5sかけてフェードインしたい fd_frm = int(fps * 0.5) #写真1枚あたりの合計フレーム数 fin = image_frm + int((fd_frm * 2)) #フェードアウトが始まるフレーム数 str_fadeout = image_frm + fd_frm |
次に、フェードイン・フェードアウトをする際に、1フレームあたりいくつずつ透明度が変化すればいいのか計算します。今回、0.5秒かけてフェードをするので、30フレームかけて、0→255になるようにします
|
1 2 3 4 |
#フェードの時の透明度の間隔 alp_spn = 255 / fd_frm #最初の透明度 フェードインしたいので、最初は透明になるようにする alp = 0 |
ここまで書けたら、あとは、写真1枚ずつからフレーム画像を生成していきます。「tmp」フォルダ内の写真を読み取り、各写真の動画用フレーム画像を順番に生成します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
slides = glob.glob(tmp_path + "*.jpg") for slide_path in slides: slide_num = slide_num + 1 print('make move' + str(slide_num)) for i in tqdm(range(1, fin, 1)): #写真の透明度管理 if(i < fd_frm): #フェードインしたい alp = int(alp + alp_spn) elif(i > str_fadeout): #フェードアウトしたい alp = int(alp - alp_spn) else: alp = 255 if(alp > 255): alp = 255 elif(alp < 0): alp = 0 #スライド写真に透過を指定していく slide = Image.open(slide_path).copy().convert('RGBA') slide.putalpha(alp) #真っ白な画像を新しく生成して、透過した画像と合成する base_img = Image.new('RGBA', slide.size, (255,255,255,255)) slide= Image.alpha_composite(base_img, slide) #フレーム画像を保存 tmp_sv_path = base_path + "frm" + DS + "frm_" + str(slide_num).zfill(4) + '_' + str(i).zfill(4) + '.png' slide.save(tmp_sv_path) |
画像を動画にする
ここまでこればあと一息です!
先ほどのフレーム画像生成処理の中に、動画生成処理を組み込んでいきます。動画生成処理を組み込んだフレーム生成処理の全容は下記のような感じになります
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
from PIL import Image, ImageOps, ImageGrab, ImageFont, ImageDraw import cv2 import glob slides = glob.glob(tmp_path + "*.jpg") #1秒当たりのフレーム枚数 fps = 60 #写真1枚当たりのフレーム数 3秒間表示したい image_frm = int(fps * 3) #フェードするフレーム数 0.5sかけてフェードインしたい fd_frm = int(fps * 0.5) #写真1枚あたりの合計フレーム数 fin = image_frm + int((fd_frm * 2)) #フェードアウトが始まるフレーム数 str_fadeout = image_frm + fd_frm #フェードの時の透明度の間隔 alp_spn = 255 / fd_frm #動画ファイルのクラスを準備 fmt = cv2.VideoWriter_fourcc('m', 'p', '4', 'v') video = cv2.VideoWriter(base_path + 'photo_slide.mp4', fmt, fps, video_size) for slide_path in slides: slide_num = slide_num + 1 print('make move' + str(slide_num)) for i in tqdm(range(1, fin, 1)): #写真の透明度管理 if(i < fd_frm): #フェードインしたい alp = int(alp + alp_spn) elif(i > str_fadeout): #フェードアウトしたい alp = int(alp - alp_spn) else: alp = 255 if(alp > 255): alp = 255 elif(alp < 0): alp = 0 #スライド写真に透過を指定していく slide = Image.open(slide_path).copy().convert('RGBA') slide.putalpha(alp) #真っ白な画像を新しく生成して、透過した画像と合成する base_img = Image.new('RGBA', slide.size, (255,255,255,255)) slide= Image.alpha_composite(base_img, slide) #フレーム画像を保存 tmp_sv_path = base_path + "frm" + DS + "frm_" + str(slide_num).zfill(4) + '_' + str(i).zfill(4) + '.png' slide.save(tmp_sv_path) #動画にフレームを追加 v = cv2.imread(tmp_sv_path) video.write(v) video.release() |
完成
このプログラムによって生成された動画を掲載します。
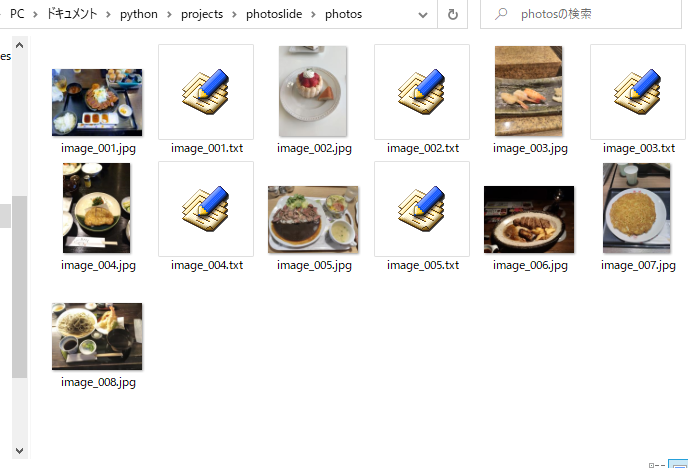
ちなみに、「photos」フォルダの中身は写真のような感じになっています。
さいごに
「動画を生成する」と聞くと、とても特殊で難しいことのように感じますが、(実際自分もどうやるの…とか思ってました…)一つずつ仕組みを調べ、実現するための関数等を調べていくと実はそこまで難しいことはないのだなと思いました!これらを応用してもっと何かつくれないかなとわくわくします。
弊社inglowでは、これから広告の運用を考えられている方、あるいはこれから広告代理店に運用をお願いされる方向けに、「業界別Web広告の成功事例」をまとめた資料を無料配布しております。
下記のフォームに入力いただくだけで、無料で資料をダウンロードしていただけます。ぜひご利用下さい。




