



pythonで楽譜画像認識
カテゴリ:Pythonの話
こんにちは。inglowの開発担当です。
今回は、近年超キテる「python」を使って、楽譜の画像から音符を認識する処理を作ってみました。
本当は音名を出すところまでやってみたかったのですが、時間の都合で断念しました……。
五線の位置と音符の位置を検出するところまでを紹介しています。
また、弊社ではWebプロモーション成功事例集をまとめた限定資料を無料で配布しています。
Webマーケティングに興味がある方は、下記ページより目を通してみてください。
開発環境は下記です。
- バージョン:python3.8.3
- ライブラリ:oepnCV4.2
- エディタ:notepad++
今回作るもの
音符の位置と五線の位置から、その音符が何の音なのかというのを判定するものを作りたかったのですが…。
五線の位置の取得がおもうようにいかず、今回は音名の表示は断念しました…。
ですが、音符の検出と、五線の検出位置の表示までは割とうまくいったので、今回はここまでをブログ記事にしました。
楽譜の著作権等の問題で、今回のテスト画像は、手書きの何の曲でもない楽譜を作成し、撮影しました。

画像の中の境界線を探す
まずは、画像の中の物体検出を行います。
検出するため、濃淡をはっきりさせて輪郭をくっきりさせて検出をします。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
#楽譜データを読み込む scr = cv2.imread(scor_img, cv2.IMREAD_COLOR) #画像のサイズを取得 pg=02 height, width, channels = scr.shape image_size = height * width #グレースケール化 ① scr_filled = cv2.cvtColor(scr, cv2.COLOR_RGB2GRAY) debug_image(scr_filled, 'note_01.png') #閾値指定してフィルタリング ② retval, dst = cv2.threshold(scr_filled, 130, 255, cv2.THRESH_TOZERO_INV ) debug_image(dst, 'note_02.png') #白黒反転 ③ dst = cv2.bitwise_not(dst) debug_image(dst, 'note_03.png') #もっかいフィルタリング retval, dst = cv2.threshold(dst, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU) debug_image(dst, 'note_04.png') #輪郭を抽出 pg=02 cnt, hierarchy = cv2.findContours(dst, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) #抽出した領域を出力 抽出した領域に境界線を引いた画像を出力 pg=02 dst = cv2.imread(scor_img, cv2.IMREAD_COLOR) dst = cv2.drawContours(dst, cnt, -1, (0, 0, 255, 255), 2, cv2.LINE_AA) cv2.imwrite(BASE_PATH + 'rinkaku.png', dst) |
影や音符等、「何か」ということは関係なく境界線を検出します。

音符を検出する
先ほど検出した物体を、今度は大きすぎるものと小さすぎるものを除いていきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
minsize = 20 #大きいor小さい領域は削除 for i, count in enumerate(cnt): #小さい領域の場合は無視 area = cv2.contourArea(count) if area < minsize: continue #画像全体を占める領域を除外 if image_size * 0.99 < area: continue #囲う線を描画する x,y,w,h = cv2.boundingRect(count) result_img = cv2.rectangle(result_img, (x, y), (x + w, y + h), (0, 255, 0), 3) |
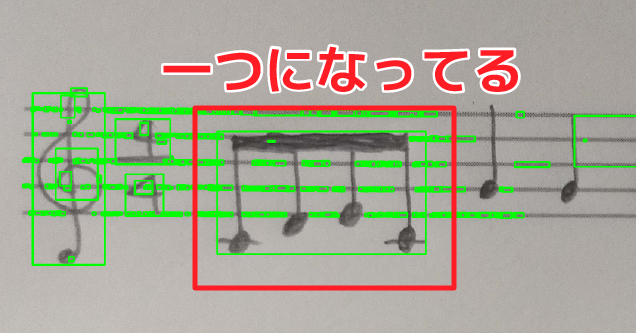
音符を検出していくのですが、八分音符が4つつながっているところが一つと認識されて、
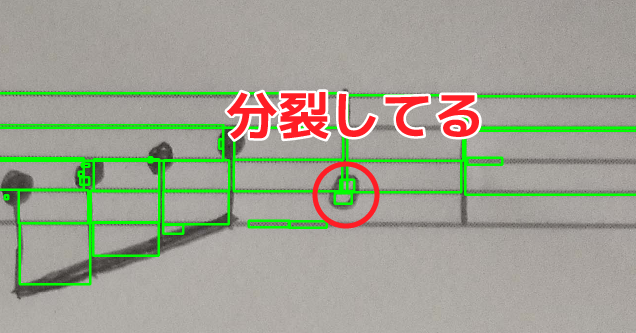
うまく音符の玉の部分が検出できません…。また、二分音符(白い玉の音符)が線をまたがっているのですが、二つに分裂されてしまっています…。
まずは、4つ連なっている八分音符を一つずつ認識してもらうため、細い線がなくなるようにぼかしの処理を入れます。

|
1 2 |
#細い線とかをぼかす ①と③のプログラムの間にこの処理を挟む scr_filled = cv2.bilateralFilter(scr_filled, 75, 75, 75) |
さらに、二分音符が分割されないよう、認識させるエリアのサイズを調整します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
#認識させるサイズを指定する pg=03 minsize = 500 maxsize = 5000 #大きいor小さい領域は削除 for i, count in enumerate(cnt): #小さい領域の場合は無視 area = cv2.contourArea(count) if area < minsize: continue #最大値の指定を追加 if area > maxsize: continue #画像全体を占める領域を除外 if image_size * 0.50 < area: continue #囲う線を描画する x,y,w,h = cv2.boundingRect(count) result_img = cv2.rectangle(result_img, (x, y), (x + w, y + h), (0, 255, 0), 3) |
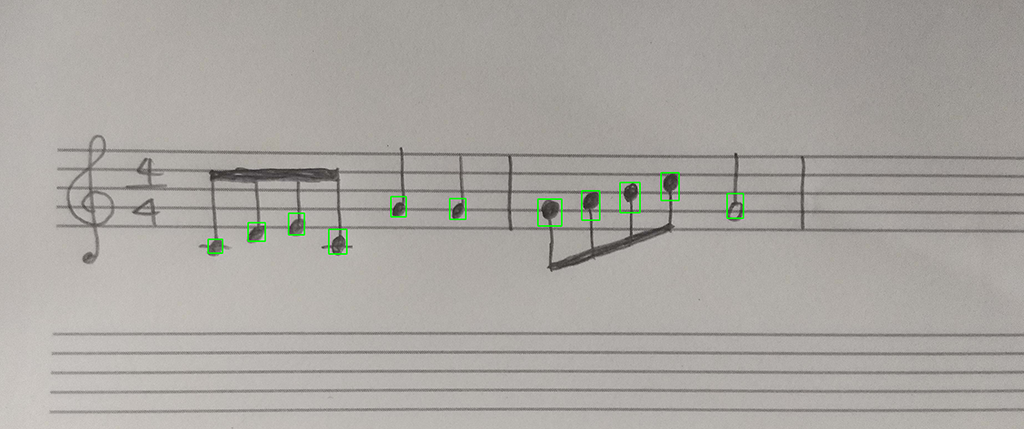
これで再度試してみたところ、うまくできました!
五線を検出する
五線の取得は、線を検出する関数を利用して検出をします。先ほどの音符を検知する時の画像は、線が消えてしまっているので、五線の検知用に新しくファイルを開きなおして、フィルタリングをしていきます。
フィルタリングした際に、線の濃淡の関係で途切れてしまったりする部分があるので、これもぼかし処理をしてつながるようにしていきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#画像を再度読み込み scr = cv2.imread(scor_img) scr_gray = cv2.cvtColor(scr, cv2.COLOR_RGB2GRAY) #途切れてるところがつながるようにぼかしてみる kval = 3 kernel = numpy.ones((kval,kval),numpy.float32)/(kval*kval) scr_gray = cv2.filter2D(scr_gray,-1,kernel) #閾値指定してフィルタリング line_retval, line_dst = cv2.threshold(scr_gray, 200, 255, cv2.THRESH_TOZERO_INV ) #白黒反転 line_dst = cv2.bitwise_not(line_dst) #もっかいフィルタリング line_retval, line_dst = cv2.threshold(line_dst, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU) #線を検出 lines = cv2.HoughLinesP(line_dst, rho=1, theta=numpy.pi/360, threshold=80, minLineLength=150, maxLineGap=100) for line in lines: x1, y1, x2, y2 = line[0] #赤線 result_img = cv2.line(result_img, (x1, y1), (x2, y2), (0,0,255), 1) |

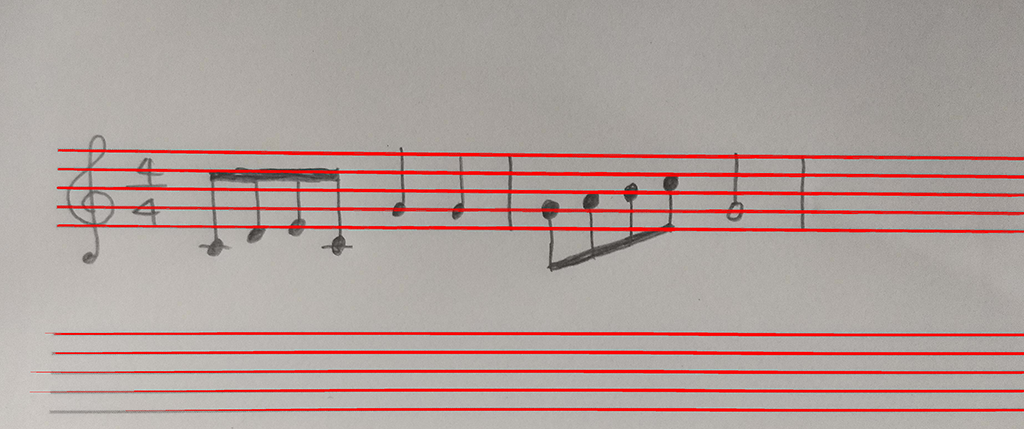
影のところや音符が連なっているところにもめっちゃ線が出てきます…。
線の検出関数の数値を調整して、なんとか五線の部分だけを認識させることができました。
|
1 2 |
#線を検出 lines = cv2.HoughLinesP(line_dst, rho=1, theta=numpy.pi/360, threshold=120, minLineLength=1000, maxLineGap=100) |
認識した音符と五線の位置を描画する
最後に、検出した音符と五線を描画していきます。
五線の方が手前にきてほしかったので、処理順を、五線認識→音符認識という順番にしました。
全体のソースと、出力結果です。
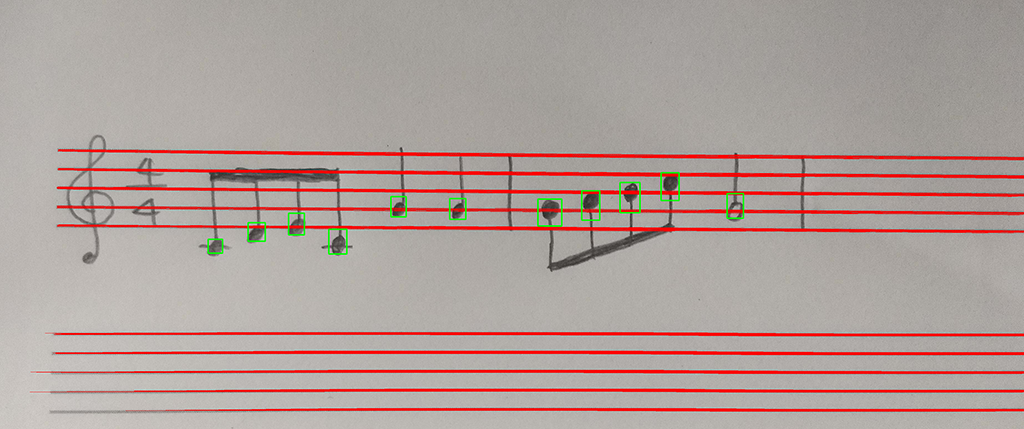
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
import numpy import cv2 import os #パスのベースを作成 DS = os.sep BASE_PATH = os.path.dirname(__file__) + DS #楽譜画像のパスを生成 scor_img = BASE_PATH + 'score' + DS + 'score.jpg' #指定したデータを指定したファイル名で出力 def debug_image(img, imgname = 'result.png'): global BASE_PATH #画像を出力 cv2.imwrite(BASE_PATH + imgname, img) result_img = cv2.imread(scor_img, cv2.IMREAD_COLOR) #五線を認識する scr = cv2.imread(scor_img) scr_gray = cv2.cvtColor(scr, cv2.COLOR_RGB2GRAY) #途切れてるところがつながるようにぼかしてみる kval = 3 kernel = numpy.ones((kval,kval),numpy.float32)/(kval*kval) scr_gray = cv2.filter2D(scr_gray,-1,kernel) #閾値指定してフィルタリング line_retval, line_dst = cv2.threshold(scr_gray, 200, 255, cv2.THRESH_TOZERO_INV ) #白黒反転 line_dst = cv2.bitwise_not(line_dst) #もっかいフィルタリング line_retval, line_dst = cv2.threshold(line_dst, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU) #線を検出 lines = cv2.HoughLinesP(line_dst, rho=1, theta=numpy.pi/360, threshold=120, minLineLength=1000, maxLineGap=100) for line in lines: x1, y1, x2, y2 = line[0] #赤線 result_img = cv2.line(result_img, (x1, y1), (x2, y2), (0,0,255), 1) #五線認識ここまで #音符のたま認識 #楽譜データを読み込む scr = cv2.imread(scor_img, cv2.IMREAD_COLOR) #画像のサイズを取得 height, width, channels = scr.shape image_size = height * width #グレースケール化 ① scr_filled = cv2.cvtColor(scr, cv2.COLOR_RGB2GRAY) #細い線とかをぼかす ぼかし処理 scr_filled = cv2.bilateralFilter(scr_filled, 75, 75, 75) #閾値指定してフィルタリング ② retval, dst = cv2.threshold(scr_filled, 130, 255, cv2.THRESH_TOZERO_INV ) #白黒反転 ③ dst = cv2.bitwise_not(dst) #もっかいフィルタリング retval, dst = cv2.threshold(dst, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU) #輪郭を抽出 cnt, hierarchy = cv2.findContours(dst, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) #抽出した領域を出力 抽出した領域に境界線を引いた画像を出力 dst = cv2.imread(scor_img, cv2.IMREAD_COLOR) dst = cv2.drawContours(dst, cnt, -1, (0, 0, 255, 255), 2, cv2.LINE_AA) #認識させるサイズを指定する minsize = 500 #20→100→500 maxsize = 5000 #元元3000とか #大きいor小さい領域は削除 for i, count in enumerate(cnt): #小さい領域の場合は無視 area = cv2.contourArea(count) if area < minsize: continue #最大値の指定を追加 if area > maxsize: continue #画像全体を占める領域を除外 if image_size * 0.50 < area: continue #囲う線を描画する x,y,w,h = cv2.boundingRect(count) result_img = cv2.rectangle(result_img, (x, y), (x + w, y + h), (0, 255, 0), 3) #音符認識ここまで #検出結果を表示 debug_image(result_img, 'result.png') |
さいごに
ここまでくればあともう一息!と思ったのですが、五線の検出データが、線1本につきたくさんあり、どこの範囲からどこの範囲までが該当エリアか、という集約で躓いてしまいました…。
時間の関係で今回はここまでで打ち止めです。くやしい…。
ですが、音符の検出まではできたので、音符のデータを学習させれば行けるんじゃないか…?と思っています。
この場合は、一つの音符を五線ごとぬきだし、学習させたデータと照合して何の音なのかを検出するという流れになるのかなと思っています。
データを学習させるために、12×1000枚(ヘ音記号も加味する場合はこれの2倍)の画像が必要なので、これまたハードルが高いですが……。
機会があれば試してみたいです。
またwebで集客する方法を別の記事にまとめております。
詳しく解説しているので、web集客について深く知りたい方は、ぜひこちらもご覧ください。

弊社inglowでは、これから広告の運用を考えられている方、あるいはこれから広告代理店に運用をお願いされる方向けに、「業界別Web広告の成功事例」をまとめた資料を無料配布しております。
下記のフォームに入力いただくだけで、無料で資料をダウンロードしていただけます。ぜひご利用下さい。




