



Pythonでスクレイピングして遊んでみる
カテゴリ:Pythonの話
こんにちは!伊神です!
この記事では、「Pythonでスクレイピングする方法」について簡単にご紹介します。
具体的には「HPのHTML情報を取得」「画像をスクレイピング」をして遊んでみました!
また、弊社ではWebプロモーション成功事例集をまとめた限定資料を無料で配布しています。
Webマーケティングに興味がある方は、下記ページより目を通してみてください。
事前準備
今回はデータ分析用のツール「Jupyter Notebook」を使用します。
Jupyter Notebookとは
Jupyter Notebook(https://jupyter.org/ ) は、ブラウザ上で動作するプログラムの対話型実行環境です。
ノートブックと呼ばれる形式で作成したプログラムを実行し、実行結果を記録しながら、データの分析作業を進めることができます。
またwebで集客する方法を別の記事にまとめております。
詳しく解説しているので、web集客について深く知りたい方は、ぜひこちらもご覧ください。

Jupyter Notebookをインストール
Anacondaという開発環境のパッケージを利用すると、Jupyter Notebookと共に、データ分析やグラフ描画など、Pythonでよく利用されるライブラリをまとめてインストールできるので便利です。
1. Python3をインストール
Pythonの公式(https://www.python.org/)からインストール
2. Anacondaをダウンロード
Anacondaの公式(https://www.anaconda.com/products/individual)からダウンロード
3. Jupyter Notebookをインストール
Jupyter Notebookの「install」ボタンを押しインストールを行います。
インストールが終わると、ボタンが「Launch」に変わりLaunchをクリックすると、Jupyter Notebookが起動します。
詳しいJupyter Notebookの使い方はこちらを参考にしてください
・https://qiita.com/takuyanin/items/8bf396e7b6b051670147
・https://code-graffiti.com/how-to-use-jupyter-notebook/
スクレイピングで遊んでみよう
HTMLを解析する
HTMLを簡単に解析できるライブラリ「Beautiful Soup」を使用します。
今回はinglow(https://inglow.jp/)のサイトをスクレイピングしました!
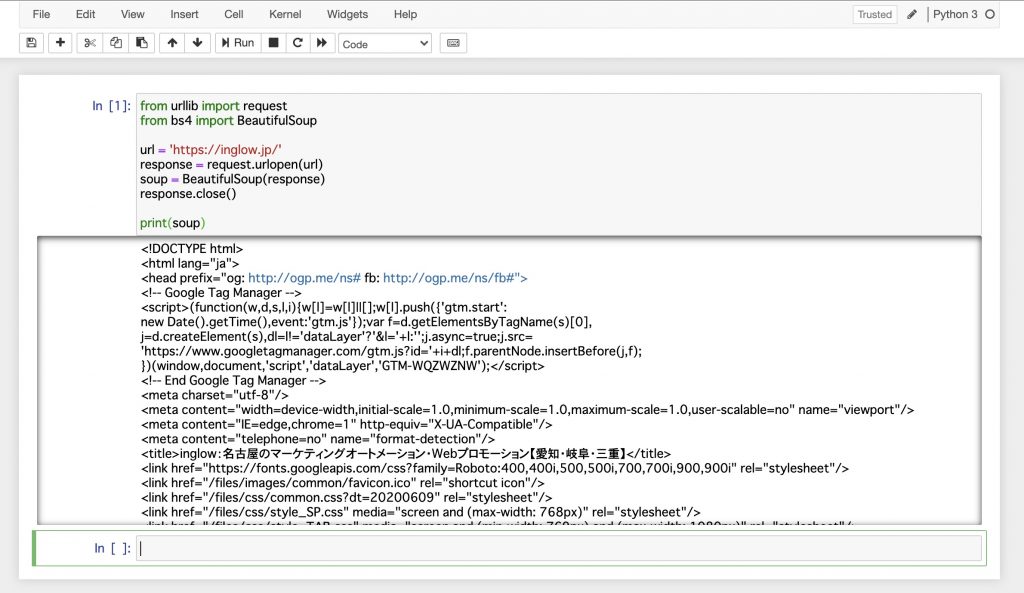
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
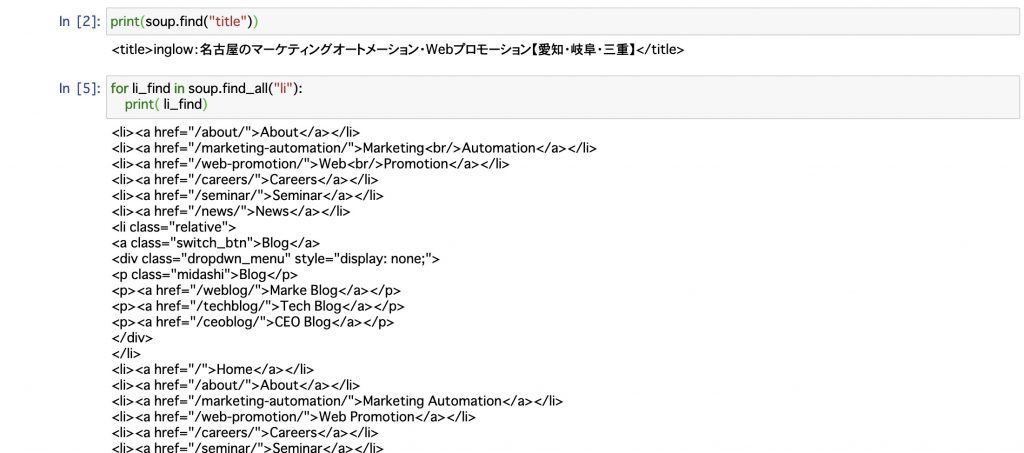
# ライブラリをインストールする from urllib import request from bs4 import BeautifulSoup # Webページを取得する url = 'https://inglow.jp/' response = request.urlopen(url) soup = BeautifulSoup(response) response.close() # HTML全体を表示する print(soup) # タイトルを表示する print(soup.find("title")) # liタグで囲まれているのを表示する for li_find in soup.find_all("li"): print( li_find) |
その他にも「id属性」や「class属性」の名前を使用して範囲を絞り込んで検索することもできます!!
画像をスクレイピング
流れとしては
Webスクレイピング→画像のURL抜き出し→URLから画像保存
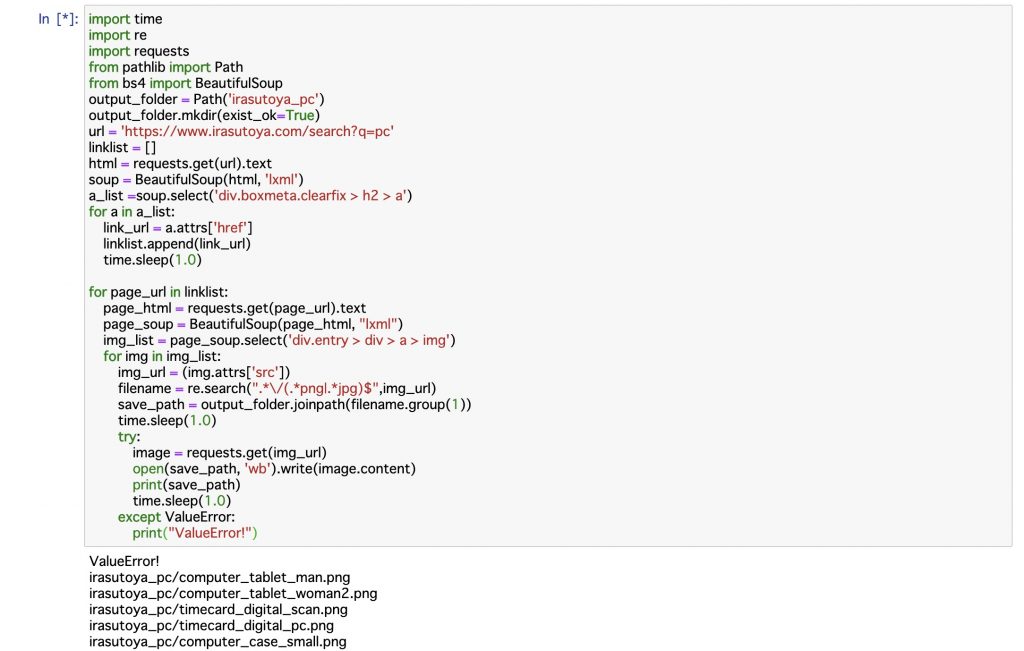
いらすとやの「pc」で検索結果画像をirasutoya_pcファイルに保存する処理を行います!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
#ライブラリのインポート import time import re import requests from pathlib import Path from bs4 import BeautifulSoup #指定したURLから画像のリンクを取得する output_folder = Path('irasutoya_pc') output_folder.mkdir(exist_ok=True) url = 'https://www.irasutoya.com/search?q=pc' linklist = [] html = requests.get(url).text soup = BeautifulSoup(html, 'lxml') a_list =soup.select('div.boxmeta.clearfix > h2 > a') for a in a_list: link_url = a.attrs['href'] linklist.append(link_url) time.sleep(1.0) # 画像リンクを一つずつ取り出して保存する for page_url in linklist: page_html = requests.get(page_url).text page_soup = BeautifulSoup(page_html, "lxml") img_list = page_soup.select('div.entry > div > a > img') for img in img_list: img_url = (img.attrs['src']) filename = re.search(".*\/(.*png|.*jpg)$",img_url) save_path = output_folder.joinpath(filename.group(1)) time.sleep(1.0) try: image = requests.get(img_url) open(save_path, 'wb').write(image.content) time.sleep(1.0) except ValueError: print("ValueError!") |

こんな感じで画像をスクレイピングすることができます!!
今回はいらすとやでスクレイピングを行いましたが、Google画像検索や違うサイトの画像も同じようにスクレイピングできるのでぜひ試してみて下さい!!
※著作権や利用規約を確認してから行って下さい。
最後に
今回はPythonでスクレイピングして遊んでみました。
pythonには様々なモジュールがあり様々なことが簡単にできたりするので是非調べてみて下さい!
弊社inglowでは、これから広告の運用を考えられている方、あるいはこれから広告代理店に運用をお願いされる方向けに、「業界別Web広告の成功事例」をまとめた資料を無料配布しております。
下記のフォームに入力いただくだけで、無料で資料をダウンロードしていただけます。ぜひご利用下さい。




