



Rubyとnokogiriを用いたスクレイピング
カテゴリ:インターン生ブログ
こんにちは。Inglowインターン生の鈴木です。
Ruby歴2ヶ月弱の僕ですが、
今回はRubyとnokogiriを用いたスクレイピングに挑戦してみました。
結論から言うと、思ってた以上に簡単でした。
その方法を簡単に記述します。
スクレイピングとは?
ウェブスクレイピング(Web scraping)とは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。ウェブ・クローラーあるいはウェブ・スパイダーとも呼ばれる。
—wikipediaより引用
つまり、特定のウェブサイトから必要な情報を取り出すことです。
実行環境
Windows10
Ruby2.4.5
Nokogiri1.10.1
準備
Rubyの環境構築は完了している前提で進めます。
まずはnokogiriをインストールします。
nokogiriはRubyでスクレイピングをする場合の定番ライブラリです。
すでにインストールされているか確認する方法は、
nokogiri -v
で確認できます。
インストール方法は
gem install nokogiri
でインストールできます
1 gem installed
と表示されれば完了です。
次に、ファイルを作成して、nokogiriを読み込みます
作成したファイルの先頭に以下の内容を記述します。
require ‘nokogiri’
require ‘open-uri’
これで準備は完了です。
実行
ここから実際スクレイピング作業をしていきます。
試しに、弊社の「ドミナント戦略について。」という記事をスクレイピングしてみます。
require ‘nokogiri’
require ‘open-uri’
[1]読み取るページのURL
url = “https://inglow.jp/weblog/%E6%9C%AA%E5%88%86%E9%A1%9E/%E3%83%89%E3%83%9F%E3%83%8A%E3%83%B3%E3%83%88%E6%88%A6%E7%95%A5%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6%E3%80%82/”
[2]URLをnokogiriで取得する
doc = Nokogiri::HTML(open(url),nil,”utf-8″)
[3]読み取る内容を指定
text = doc.xpath(‘//*[@id=”blogDetailArea”]/div/div/div[3]/p’).inner_text
[4]読み取った内容を出力
puts text
出力結果が
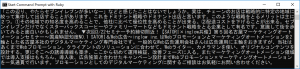
となります。
nokogiriでは読み取る内容をcssかxpathで指定することが可能です。
今回は本文の<p>タグで囲まれた内容を表示させてみました。
まとめ
今回はスクレイピングの基本的な技術を記述しました。
応用すれば様々な使い方ができそうです。
スクレイピングそのものはあまり難しいものではないのでぜひ皆さんも挑戦してみてください。
inglow inc.はWebプロモーションとマーケティングオートメーションを2軸とした名古屋本社のデジタルマーケティング専門会社です。一般的なWeb広告運用会社さんは広告運用に主軸をおきますが、当社はあくまでWebプロモーション。クライアントのソリューションに合わせて、Webライター、カメラマンを使い、オリジナルコンテンツを設計する。更にそこへの誘導導線も築き、ここから初めて運用検証、改善フェーズに入る。またマーケティングオートメーション領域では導入支援はもちろん、導入後、広告施策と合わせたキャンペーン設計までWebプロモーション×マーケティングオートメーションを一気通貫で行います。
プロモーションとしてのデジタルマーケティングに関するご相談はお気軽にお問い合わせください。
| 株式会社inglow | |
| 事業ドメイン | マーケティングオートメーション導入・伴走サポート |
| Webプロモーションの戦略立案・実行 | |
| メール(お問い合わせ) | info@inglow.jp |
| 電話番号 | 052-218-2660 |
| 住所 | 愛知県名古屋市中区丸の内2-18-22三博ビル7F |



